
最近在看研究公司业务的存储架构,现有的存储用redis 和 leveldb 通过自己写的中间件做数据落地。这样写业务和数据恢复有点麻烦,想着优化一下,就去研究redis和leveldb的源码。发现了跳表这个数据结构很有意思,性能不错,实现也相对简单,就想着自己用go实现一个跳表,在通过这个跳表实现一个类似redis 的 zset 功能。我会尽可能 详细的去介绍所有实现细节。
看着篇文章,首先熟悉链表的相关知识,比如链表的插入和删除。最好会一点go,不会关系也不大,go的语法很简单,和C有一点像,有计算机基础的基本很快就能看懂go的语法。
下面分这个几点来介绍
- 跳表是什么
- 跳表的优缺点
- 跳表的结构
- 怎么实现一个跳表(增删改查)
跳表是什么
跳表是一个可以快速查找的有序链表, 搜索、插入、删除操作的时间均为O(logn), 关于跳表的详细定义 维基百科 百度百科 跳表虽然是非常有用的数据结构,但是很多书里都没有写这个,我在大学的数据结构课本里也没有写跳表,就导致很多人对跳表不熟悉。
跳表本质上是一个链表,因为链表的随机查找性能太差,是O(N),查找元素只能从头结点或者尾结点遍历。

如图中要查找结点6,只能从结点1 一点点往右遍历。
能不能在链表中使用二分查找呢,当然是可以的,就是给链表加索引,也就是跳表了
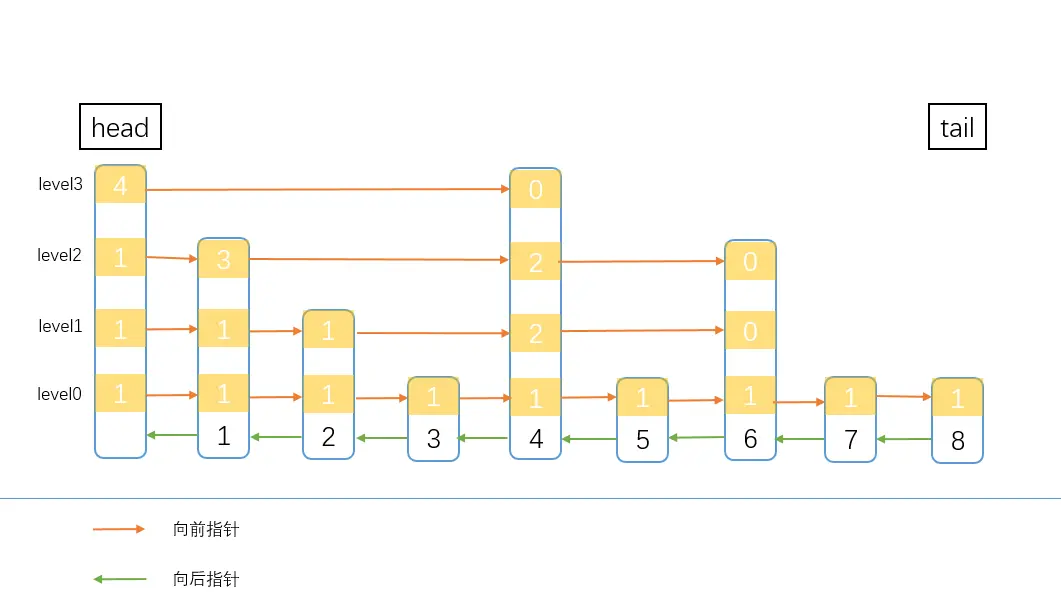
上图就是一个简单的跳表了(图中的各种颜色和数字后面会有详细的介绍)。从图中可以看出,跳表是在双向链表的基础上,加了多层索引实现的。
跳表的优缺点
作为快速查找的数据结构,跳表常用来和红黑树 做比较,列一下跳表和红黑树的优缺点吧
- 跳表的优点:
- 跳表实现起来相对简单。红黑树的定义和左旋右旋操作,确实复杂,我资质愚钝,理解起来还是有单困难。后面我会解释跳表实现简单的原因的.
- 区间查找方便。在跳表中找到一个节点后,就可以通过前后指针找到相邻的元素。红黑树则需要通过父节点,子节点去寻找,相对麻烦。
- 红黑树的优点
- 内存占用小,只需要3个指针就可以(左子树,右子树,父节点) 而跳表有一个向后的指针,每一层都有一个向前的指针
- 红黑树的查找稳定,红黑树有着严格的定义,每次插入和删除数据都会通过左旋右旋来平衡树的结构,通过红黑树查找有着稳定的查找时间O(logn) ,为啥跳表是不稳定的,看到跳表是怎样确定层数的就明白了
- 跳表和普通链表相比,除了费内存,好像没啥缺点了
跳表的结构和实现
跳表的实现思路借鉴了redis的zset实现思想具体代码在github 跳表简单说可以有两种实现思路,一种是跳表内不能有重复的元素,另一种是跳表内允许有重复元素。redis中的跳表是允许有重复元素的,我这次实现的也是可以有重复元素的。
跳表node 的结构
1type SkipListLevel struct {
2 //指向下一个结点
3 forward *SkipListNode
4
5 /*
6 * 到下一个node的距离;
7 * 思考,为啥是记录到下一个node, 而不是记录上一个node到这的距离
8 */
9 span int64
10}
11
12type SkipListNode struct {
13 //指向上一个结点
14 backward *SkipListNode
15 //索引用的层
16 level []SkipListLevel
17 //存储的值
18 value ISkipListNode
19 //排名用的分数
20 score float64
21}
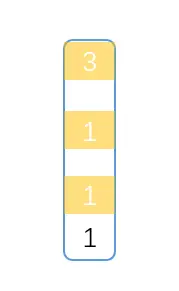
在一个node中,黑色的1是 value, 黄色的方块是level,白色的数字是span,backward 和 forward 这两个指针在图中没有体现出来,只会有一个backward (向后的指针),level数组长度是多少,就会有多少个forward(向前的)指针。 span值是到下一个结点的跨度是多少,相邻的结点数值是1。这个值的作用是用来计算这个node在跳表中的排名。一开始我对span的值 不理解,以为是上个结点到这里的距离,直到在写插入和搜索结点的时候,才意识到这个是到下个结点的跨度。
跳表结构
1type SkipList struct {
2 //头结点和尾结点
3 //重点,头结点是一个真实存在的,尾结点只是一个指针
4 head, tail *SkipListNode
5
6 size int64 //node总数
7
8 level int //当前跳表的最高level
9
10 maxLevel int //当前最大层数
11}
head 和 tail 是两个指针指向跳表的头和尾,size 是整个跳表中node的的数量, level 是跳表中,当前的最大高度,这里会引申出一个知识点,跳表中的高度不是固定不变的,而是随着插入和删除动态变化的。maxLevel 是跳表可以达到的最大高度,这个值是一开始就固定的不变的。
再把上面的图拿过来,分析一下整个跳表结点间的组织关系
跳表中会有一个 head 结点,但是没有 tail 结点,tail只是一个指针,指向跳表的最后一个结点。这个在初始化函数里有体现
1//初始化一个默认的跳表
2func NewDefaultSkipTable() *SkipList {
3 rand.Seed(time.Now().UnixNano())
4 return &SkipList{
5 head: NewSkipListNode(SKIP_TABLE_DEFAULT_MAX_LEVEL, 0, nil),
6 size: 0,
7 level: 1,
8 maxLevel: SKIP_TABLE_DEFAULT_MAX_LEVEL,
9 }
10}
图中向前的指针 (forward),也就是橙色的箭头,向后的指针 (backward),也就是绿色的箭头。 forward指针在level中,也就是每一层都有一个向前的指针,backward只存在于node中,也就是每个节点只有一个向后的指针。想一下为啥只需要一个向后的指针呢???看完整个查找过程就明白为啥只需要一个向后指针就行了。
插入node
基础知识准备的差不多了,开始进入跳表的插入逻辑,先通过一张图把逻辑展示一下
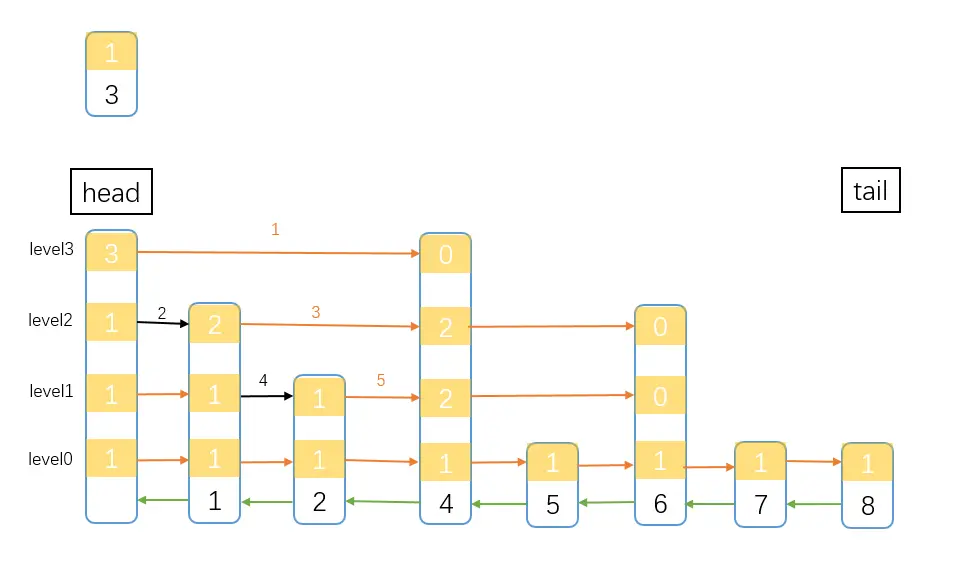
插入元素的第一步就是先查找元素。因为是有序链表,元素都是按序排列的,插入元素前先找到元素应该在的位置。
图中要把score为3的元素插入跳表中,带序号的箭头(指针)是搜索顺序,其中黑色的箭头是实际确定的路径,在搜索过程中,还要记录一下rank,也就是经过所有node的span之和。 先明确一下我们要搜索的结点是哪个。我们要找一个小于3的最大的数(先不考小数和虑链表中有多个3的情况),体现在图中,也就是我们要找到元素2的位置。
搜索前先确定 当前跳表的最高level值。也可以无脑从最上层开始,但是没有意义。图中最高level是4,也就是level3(因为level数组从0开始)。然后从头结点(head)的level层(level3)开始。
先设一个临时指针 t 指向head结点。 先通过图中 1 指针,指向的是元素4,要插入的节点是3,这个明显是大于3的,所以不符合。划重点了 当 现在的node当前层的下一个node不符合条件时,就需要开始搜索下一层 这算是一个转移条件吧。 这时候当前node还是在head,所以从head的level2开始向右搜索。此时node的下一个node是1,1小于3,所以符合条件,所以 t 指针要指向 1 node,再记录一下head的span值。
如此往复,经过 3 4 5 指针的判断,最终来到了node 2 的level0,这时node2的下一个node是大于3的,而此时也是最后一层了,所以node 2 就是小于3 的最大值了,也就是要找的元素。
找到合适的位置,接下来就是把node 3 插入进去了,并把span调整一下。
在确定好要插入的位置后,还要确定node3元素的level高度,这个高度按照理想状态跳表中间的node是最高的,类似一个 山 字型,山字的左半边,再找到中间的node,这个node是次高的,以此类推。但实际上,跳表没有严格执行这种理想状态,node的高度是通过 随机 数确定的,你没看错,就是通过随机数确定。这也就是跳表相对红黑树实现起来简单的原因。
这是随机函数
1//跳表加一层索引的概率
2var SKIPLIST_P = 0.25
3
4//随机索引的层数
5func (list *SkipList) randLevel() int {
6 level := 1
7 for (rand.Uint32()&0xFFFF) < uint32(0xFFFF*SKIPLIST_P) && level < list.maxLevel {
8 level++
9 }
10 return level
11}
1func (list *SkipList) randLevel() int {
2 level := 1
3 for rand.Int31n(100) < 25 && level < list.maxLevel {
4 level++
5 }
6 return level
7}
上面这两段函数功能都是一样的,都是25%的概率让node 的 level 数+1。
下面就是整个插入node的源码
1//插入一个结点
2func (list *SkipList) InsertByScore(score float64, value ISkipListNode) *SkipListNode {
3 rank := make([]int64, list.maxLevel)
4 update := make([]*SkipListNode, list.maxLevel)
5 t := list.head
6 //搜索node
7 for i := list.level - 1; i >= 0; i-- {
8 if i == list.level-1 {
9 rank[i] = 0
10 } else {
11 rank[i] = rank[i+1]
12 }
13 //当前层的下一个结点存在 && (下一个结点score<score || 当score相同时,比较这两个结点,下一个结点<新插入的结点)
14 for t.Next(i) != nil && (t.Next(i).score < score || (t.Next(i).score == value.Score() && t.Next(i).value.Compare(value) < 0)) {
15 rank[i] += t.level[i].span
16 t = t.Next(i)
17 }
18 update[i] = t
19 }
20
21 level := list.randLevel()
22
23 if level > list.level {
24 //处理rand level后, level>当前level后的情况
25 for i := list.level; i < level; i++ {
26 rank[i] = 0
27 update[i] = list.head
28 update[i].SetSpan(i, list.size)
29 }
30 list.level = level
31 }
32 newNode := NewSkipListNode(level, score, value)
33 //插入新的node
34 for i := 0; i < level; i++ {
35 newNode.SetNext(i, update[i].Next(i))
36 update[i].SetNext(i, newNode)
37
38 newNode.SetSpan(i, update[i].Span(i)-(rank[0]-rank[i]))
39 update[i].SetSpan(i, rank[0]-rank[i]+1)
40 }
41
42 //处理新增结点的span
43 for i := level; i < list.level; i++ {
44 update[i].level[i].span++
45 }
46 //处理新节点的后退指针
47 if update[0] == list.head {
48 newNode.backward = nil
49 } else {
50 newNode.backward = update[0]
51 }
52
53 //判断新插入的节点是不是最后一个节点
54 if newNode.Next(0) != nil {
55 newNode.Next(0).backward = newNode
56 } else {
57 //如果是最后一个节点,就让tail指针指向这新插入的节点
58 list.tail = newNode
59 }
60 list.size++
61 return newNode
62}
在搜索过程中,需要一个 rank 数组和一个 update 数组 这两个辅助结构。 rank用来记录每层的排名值,用来后面调整新node 的rank 使用。 update用来记录从上而下经过的路径,也就是新node的每一层在跳表中的上一个node。
1 //当前层的下一个结点存在 && (下一个结点score<score || 当score相同时,比较这两个结点,下一个结点<新插入的结点)
2 for t.Next(i) != nil && (t.Next(i).score < score || (t.Next(i).score == value.Score() && t.Next(i).value.Compare(value) < 0)) {
3 rank[i] += t.level[i].span
4 t = t.Next(i)
5 }
上面是搜索过程中,判断是右移还是调到下一层的逻辑。这里不止需要判断node的socore,还要考虑两个node 的 score相同的情况,两个node 的 socre相同时,需要通过Compare 函数判断两个node的大小。
1 level := list.randLevel()
2 if level > list.level {
3 //处理rand level后, level>当前level后的情况
4 for i := list.level; i < level; i++ {
5 rank[i] = 0
6 update[i] = list.head
7 update[i].SetSpan(i, list.size)
8 }
9 list.level = level
10 }
这段代码,是确定新node的高度后,处理一下新加层的。因为在搜索的时候,没有把现在高出层数的head放到update中,现在放到其中。
1 //插入新的node
2 for i := 0; i < level; i++ {
3 newNode.SetNext(i, update[i].Next(i))
4 update[i].SetNext(i, newNode)
5
6 newNode.SetSpan(i, update[i].Span(i)-(rank[0]-rank[i]))
7 update[i].SetSpan(i, rank[0]-rank[i]+1)
8 }
这段代码是通过调整node的前后指针,将新的node加入到跳表中。并且调整node的span值。这时候,span值是到下个node的距离而不是上个node到这的距离的好处就提现出来了,因为是到下个node的距离,只需要改当前node的span值就好了,如果存的是上个node到这个node的距离,就需要改下个node的span了,改动起了就会麻烦了。说的可能有点啰嗦,自己推导一遍就能体会出来了。
1 //处理新增结点的span
2 for i := level; i < list.level; i++ {
3 update[i].level[i].span++
4 }
这段可能是不太好理解的,这段代码的作用是,如果新node的level小于跳表中的最大level时(新node的level是2,此时跳表中最大的level是5的情况),这时候要把2上面的所有的node的span+1。
剩下的,处理新node的后退指针(backward)和判断是否是最后一个node,的情况就很简单了。
到现在,插入node就完成了,是不是也不难嘛,对不对。其实跳表中最复杂的就是插入过程了,剩下的删除,更新,查找就是差不多的逻辑,先找到关键node,再做处理。
删除node
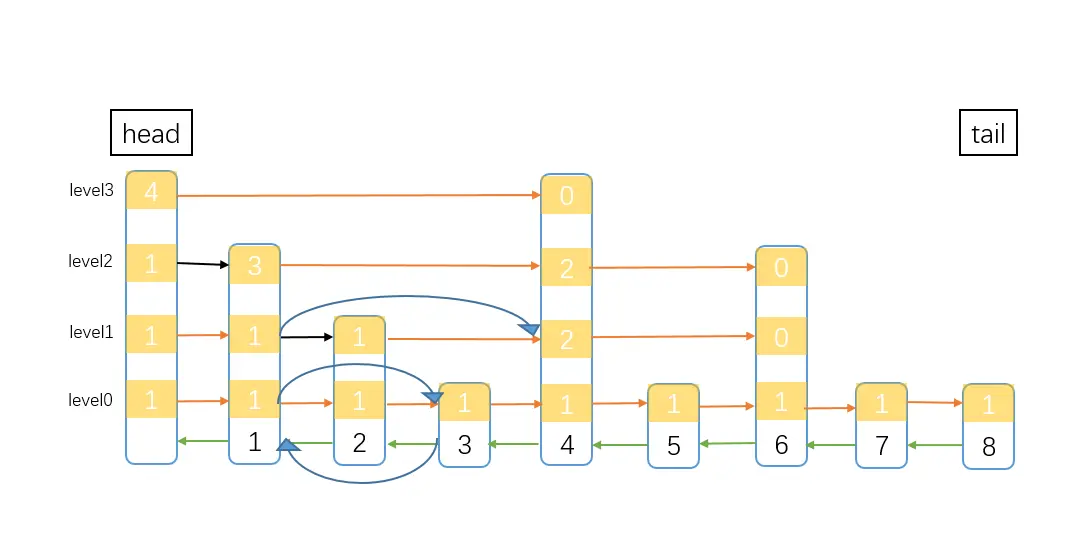
同样的,删除也是要先搜索,通过黑色箭头的路径,找到要删除的node前一个,然后修改目标node的上一个node的指针,跳过目标node,完成删除,最后调整目标node前面node的span值。
先搜索node,并记录到update数组
1//获取找到该结点的各层结点(路径)
2func (list *SkipList) GetUpdateList(node *SkipListNode) (update []*SkipListNode) {
3 update = make([]*SkipListNode, list.maxLevel)
4 t := list.head
5 for i := list.level - 1; i >= 0; i-- {
6 for t.Next(i) != nil && (t.Next(i).score < node.score || (t.Next(i).score == node.score && t.Next(i).value.Compare(node.value) < 0)) {
7 t = t.Next(i)
8 }
9 update[i] = t
10 }
11 return
12}
这段逻辑和插入时的搜索逻辑一样
下面是删除的逻辑
1//删除对应的结点
2func (list *SkipList) Delete(node *SkipListNode, update []*SkipListNode) {
3 if node == nil {
4 return
5 }
6 //head 不能删
7 if node == list.head {
8 return
9 }
10
11 for i := 0; i < list.level; i++ {
12 if update[i].Next(i) == node {
13 //修改span
14 update[i].SetSpan(i, update[i].Span(i)+node.Span(i)-1)
15 //删除对应的结点
16 update[i].SetNext(i, node.Next(i))
17 } else {
18 update[i].level[i].span--
19 }
20 }
21
22 //处理node的后指针
23 if node.Next(0) == nil { //node是最后一个,把tail指针指向node的上一个(update[0])
24 list.tail = update[0]
25 } else { //node不是最后一个,node的下一个指向node的上一个(update[0])
26 node.Next(0).backward = update[0]
27 }
28
29 //处理删掉的是最高level的情况,当前的level要对应的--
30 for list.level > 1 && list.head.Next(list.level-1) == nil {
31 list.level--
32 }
33
34 list.size--
35}
删除node的代码就简单多了,这里通过参数传入从最高到找到node的路径,也就是update数组。
1 for i := 0; i < list.level; i++ {
2 if update[i].Next(i) == node {
3 //修改span
4 update[i].SetSpan(i, update[i].Span(i)+node.Span(i)-1)
5 //删除对应的结点
6 update[i].SetNext(i, node.Next(i))
7 } else {
8 update[i].level[i].span--
9 }
10 }
这个段逻辑就是删除node的,删除说白了就是让目标node的前面的node的后指针指向目标node后面的node。 剩下的就是处理node的后退指针和判断是否是最后一个node了。
更新node
1//更新结点的score
2func (list *SkipList) UpdateScore(node *SkipListNode, score float64) {
3 if score == node.score {
4 return
5 }
6 //更新后,分数还是 < next node的位置不用变
7 if score > node.score {
8 if node.Next(0) != nil && score < node.Next(0).score {
9 node.score = score
10 return
11 }
12 }
13
14 //更新后,分数还是 > per node的位置不用变
15 if score < node.score {
16 if node.Pre() != nil && score > node.Pre().score {
17 node.score = score
18 return
19 }
20 }
21 //删掉node,重新插入
22 updateList := list.GetUpdateList(node)
23 list.Delete(node, updateList)
24 //重新插入
25 list.InsertByScore(score, node.value)
26}
更新node的score,更新node的前提是找到目标node,原理和前面的插入,删除时的搜索逻辑一样,就不赘述了。 说一下更新node score的逻辑把,最简单就是把node删了,然后再插入。当然这样的逻辑是可以优化的,比如有一种情况
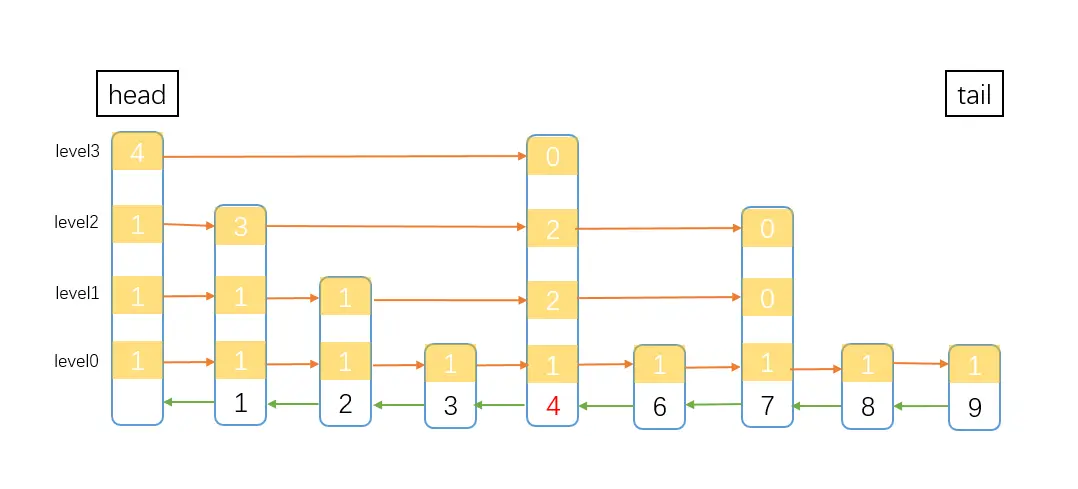
如图所示,要把node4的score更新成5,这时候修改node的score不影响node的位置,所以这种情况就只需要修改node的score就好了,不用考虑node在跳表中的位置。
对于那种修改分数会改变位置的情况,就需要先删除node,再重新插入node了。
查找node
看到这里,查找node应该是非常简单了吧,因为前面的插入,更新,删除都需要前查找node。但是查找分两种情况,一种是根据排名查找,另一种是根据score查找。
先看根据排名查找
1//根据排名 范围 查找 node
2func (list *SkipList) GetNodeByRank(left, right int64) (result []*SkipListNode) {
3 //范围出错
4 if list.Size() == 0 || left == 0 || right == 0 || right < left || left > list.Size() {
5 return
6 }
7 tRank := int64(0)
8 t := list.head
9 result = make([]*SkipListNode, 0, right-left+1)
10 //先找到排名最小的元素,然后向右一点点查找,直到找到排名最大的元素
11 for i := list.level - 1; i >= 0; i-- {
12 for t.Next(i) != nil && tRank+t.level[i].span <= left {
13 tRank += t.level[i].span
14 t = t.Next(i)
15 }
16 if tRank == left {
17 for ; t != nil && tRank <= right; t = t.Next(0) {
18 result = append(result, t)
19 tRank++
20 }
21 return
22 }
23 }
24 return
25}
先排除不符合的情况,再根据之前的查找逻辑,一步步去查找。不同的是,现在的限制条件时排名。
在看根据score查找
1
2//判断 这个跳表 的最大值和最小值 是否包含 要查询的score范围
3func (list *SkipList) ScoreInRange(findRange *SkipListFindRange) bool {
4 if !findRange.MaxInf && list.head.Next(0).score > findRange.Max {
5 return false
6 }
7 if !findRange.MinInf && list.tail.score < findRange.Min {
8 return false
9 }
10 return true
11}
12
13//根据 score 范围 查找 node
14func (list *SkipList) GetNodeByScore(findRange *SkipListFindRange) (result []*SkipListNode) {
15 if findRange == nil || list.Size() == 0 {
16 return
17 }
18 //查找范围不在这跳表中,直接return
19 if !list.ScoreInRange(findRange) {
20 return
21 }
22 t := list.head
23 if findRange.MinInf {
24 //从头开始查找
25 t = list.head.Next(0)
26 } else {
27 //不是从头,找到最小的那个元素
28 for i := list.level - 1; i >= 0; i-- {
29 for t.Next(i) != nil && t.Next(i).score < findRange.Min {
30 t = t.Next(i)
31 }
32 }
33 }
34 for {
35 //符合范围的条件 (从负无穷 || 当前的score >= 查找的最小值) && (到正无穷 || 当前元素 <= 查找的最大值)
36 if (findRange.MinInf || t.score >= findRange.Min) && (findRange.MaxInf || t.score <= findRange.Max) {
37 result = append(result, t)
38 }
39 if t.Next(0) == nil || (!findRange.MaxInf && t.Next(0).score > findRange.Max) {
40 //下一个元素是空(到尾了) || (不是查找到正无穷 && 下一个元素的 score > 要查找的最大值)
41 break
42 } else {
43 //向右移动
44 t = t.Next(0)
45 }
46 }
47 return
48}
根据score查找稍微复杂一点,因为根据score会有正无穷和负无穷这两种情况。这时候只给两个简单的范围值就不够用了,需要用一个结构体来描述范围了。
1//根据scores查找元素的条件
2type SkipListFindRange struct {
3 Min, Max float64 //最大值和最小值
4 MinInf, MaxInf bool //是否是正无穷和负无穷
5}
在查找前先判断一下,给定的范围是否在跳表的范围内,如果不在就不用查找了。
1 t := list.head
2 if findRange.MinInf {
3 //从头开始查找
4 t = list.head.Next(0)
5 } else {
6 //不是从头,找到最小的那个元素
7 for i := list.level - 1; i >= 0; i-- {
8 for t.Next(i) != nil && t.Next(i).score < findRange.Min {
9 t = t.Next(i)
10 }
11 }
12 }
这段逻辑是确定查找的开始位置也就是找到目标node(根据范围找到最小的node),如果是从负无穷开始,就不用通过之前的方式去确定开始node了,直接从head开始就好了。 后面的逻辑就没什么特别的,找到目标弄的后,开始往后找,直到最后或者不符合范围了,就结束。
好了查找也完成了。
跳表的基本功能到现在已经完成,剩下的就是把跳表包装一层,去实现redis中zset的功能就好了。具体代码就不贴了,最后我会给出github的连接。
总结
- 跳表可以看做一个支持二分查找的有序双向链表
- 跳表中最核心的就是搜索,不管是在插入,更新,删除还是查找中,都要先搜索
- 跳表在插入node时,通过随机数确定node中层数的
- 跳表的node中,有一个向后的指针,在每一层中有一个向前的指针
- 跳表相对于红黑树,优势是相对容易实现,和范围查找方便
最后在说一下常见的跳表的应用吧。redis 的zset就是基于跳表实现的,当然我也是通过读redis的源码,学习跳表的。还有一个是Google开发的 leveldb 也是基于跳表实现的。
如果这个文章对你有帮助记得给我点个star 谢谢了