
一直以来算法题刷的比较少,算法这块算是我的弱项。前几天,看到一个挺有意思的链表题
原题
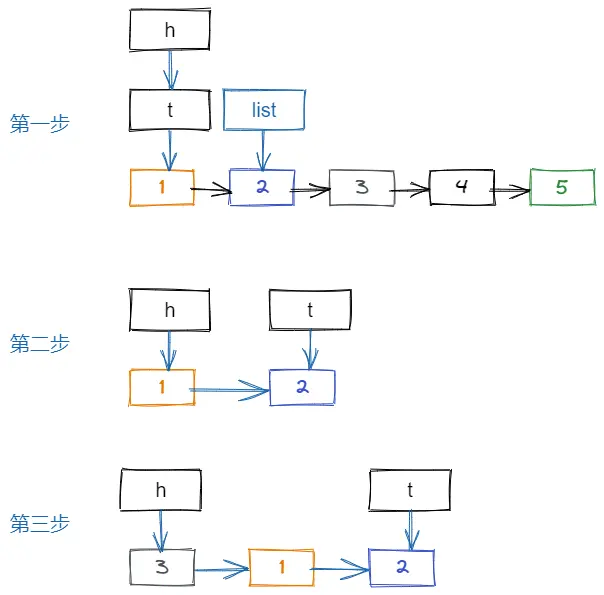
原题是这样的,给一个链表 [1,2,3,4,5] 然后转换成 [5,3,1,2,4] 这种格式
找一下规律,其实就是第一个先拿第一个元素,然后把第二个元素放在新的链表后面,第三个元素放在新的链表前面,然后第四个放在新链表的后面,第五个放在新链表前面,以此类推。
其实就是一个链表头插和尾插的结合嘛
直接上代码
1package main
2
3import (
4 "fmt"
5)
6
7type Node struct {
8 Next *Node
9 Val int
10}
11
12//通过数组生成链表
13func Make(nums []int) *Node {
14 head := &Node{}
15 move := head
16 for _, num := range nums {
17 t := &Node{
18 Val: num,
19 }
20 move.Next = t
21 move = move.Next
22 }
23 return head.Next
24}
25
26//打印链表
27func Print(list *Node) {
28 for h := list; h != nil; h = h.Next {
29 fmt.Printf("%d ", h.Val)
30 }
31 fmt.Println()
32}
33
34func main() {
35 nums := make([]int, 5)
36 for i := 1; i <= 5; i++ {
37 nums[i-1] = i
38 }
39 nodes := Make(nums)
40 Print(nodes)
41 nodes = TurnList(nodes)
42 Print(nodes)
43}
44
45//转换链表
46func TurnList(list *Node) *Node {
47 i := 0
48 h := list
49 t := list
50 list = list.Next
51 for list != nil {
52 if i%2 == 0 {
53 t.Next = list
54 list = list.Next
55 t = t.Next
56 t.Next = nil
57 } else {
58 x := list.Next
59 list.Next = h
60 h = list
61 list = x
62 }
63 i++
64 }
65 return h
66}
初始链表如图:

变换过程:
只写这一个也抬不过瘾了,再来一个链表排序的 leetcode 148
链表排序
排序的方法有好多,但是我感觉适合用于链表的是 插入排序 和 归并排序 尤其是归并排序,简直就是为链表定做的。
先来一个简单的,插入排序吧
插入排序的思想就是选择一个基准,然后把整个序列中的比自己小的放到基准的前面,用数组的形式还是很好理解和操作的。但是链表不能随机访问,所以不能用数组那样的插入排序了,需要做一下变换,看起来有点像是选择排序和插入排序的结合。 不废话了,直接上代码,插入排序:
1func InsertSort(list *Node) *Node {
2 head := &Node{
3 Next: list,
4 }
5 h := head
6 for h.Next != nil {
7 t := h
8 for t.Next != nil {
9 if t.Next.Val < h.Next.Val {
10 x := t.Next
11 t.Next = t.Next.Next
12 x.Next = h.Next
13 h.Next = x
14 } else {
15 t = t.Next
16 }
17 }
18 h = h.Next
19 }
20 return head.Next
21}
无序的链表

排序过程
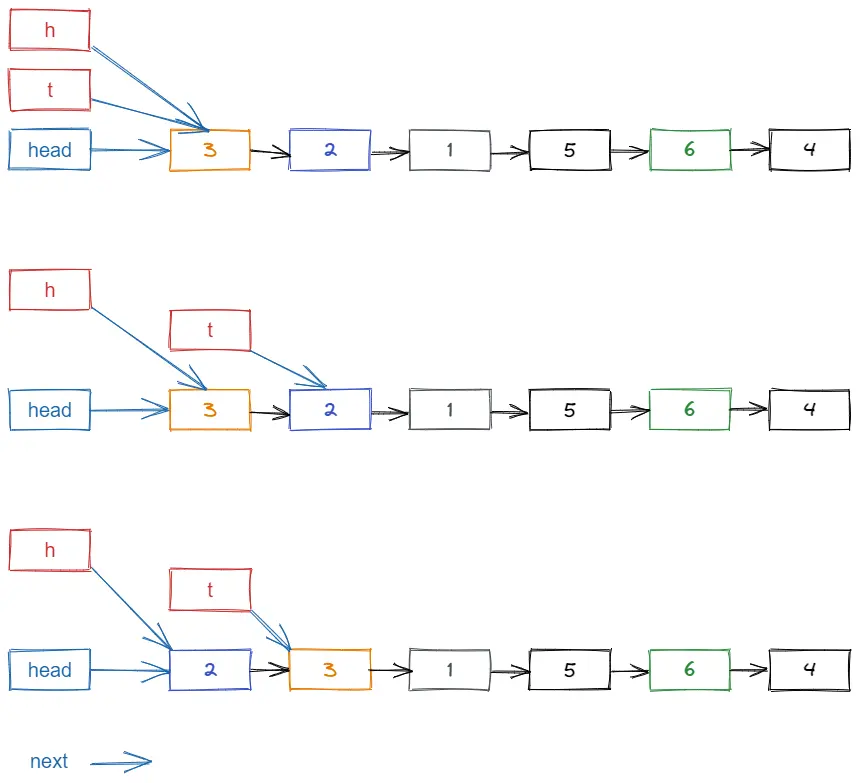
图中有个迷惑的地方,就是蓝色的线是 next 指针的指向,就是一开始的时候,head h t 的next指针指向 3
也就是 h t自身是指向 head的,head是一开始的时候,新建的一个临时结点,因为单向链表无法向前查找,只能向后查找,所以要用 next 指针。
同样,在使用 t 和 h 指针的时候,也都是使用 next 用来判断。
比较逻辑 t.Next.Val < h.Next.Val 当 t的 next 是 3,h的 next 是 2 时,满足条件,所以交换 2 和 3
如此往复,当 t 走完一趟后,链表中的第一个结点就是最小的了。
当 t 走完一趟后,h指针要后移一个。以此类推,直到 h 和 t 都走完后,就完成了排序。
这个排序方法用的是插入排序的思想加上一些选择排序的方法完成的,时间复杂度还是O(n²)。是稳定的排序。
归并排序
相比插入排序和选择排序,归并排序就要复杂一些了
归并排序的思想是分治法,把整个序列拆分,当拆分到不能再拆分时,子序列就是有序的了。也就是当序列长度是1的时候,序列就是有序的。然后在把子序列有序的合并起来。
归并排序简直就是为了链表排序而生的。如果用数组排序,拆分和重组还是比较复杂的,链表就简单多了。说实话,数组的归并排序我都不会写。
线上代码,归并排序
1func MergerSort(list *Node) *Node {
2 if list == nil || list.Next == nil {
3 return list
4 }
5
6 fast := list.Next
7 slow := list
8 for fast != nil && fast.Next != nil {
9 fast = fast.Next.Next
10 slow = slow.Next
11 }
12
13 h1 := MergerSort(slow.Next)
14 slow.Next = nil
15 h2 := MergerSort(list)
16
17 return Merge(h1, h2)
18}
19
20func Merge(list1, list2 *Node) *Node {
21 head := &Node{}
22 h := head
23 for list1 != nil && list2 != nil {
24 if list1.Val < list2.Val {
25 h.Next = list1
26 list1 = list1.Next
27 } else {
28 h.Next = list2
29 list2 = list2.Next
30 }
31 h = h.Next
32 }
33 if list1 != nil {
34 h.Next = list1
35 } else {
36 h.Next = list2
37 }
38 return head.Next
39}
归并排序有两个部分,一个是拆分,另一个是合并。
拆分 拆分是二分法,也就是每次从中间分开。链表中找到中间位置,最方便的就是快慢指针了,就是一个指针每次移动一个位置,指针每次移动两个位置。当快的指针移动到最后的时候,慢的指针正好移动到链表的中间位置。递归拆分,直到链表长度是1的时候,就完成了拆分。
合并 合并的过程其实就是合并两个有序链表。leetcode 21 很简单没什么需要解释的。
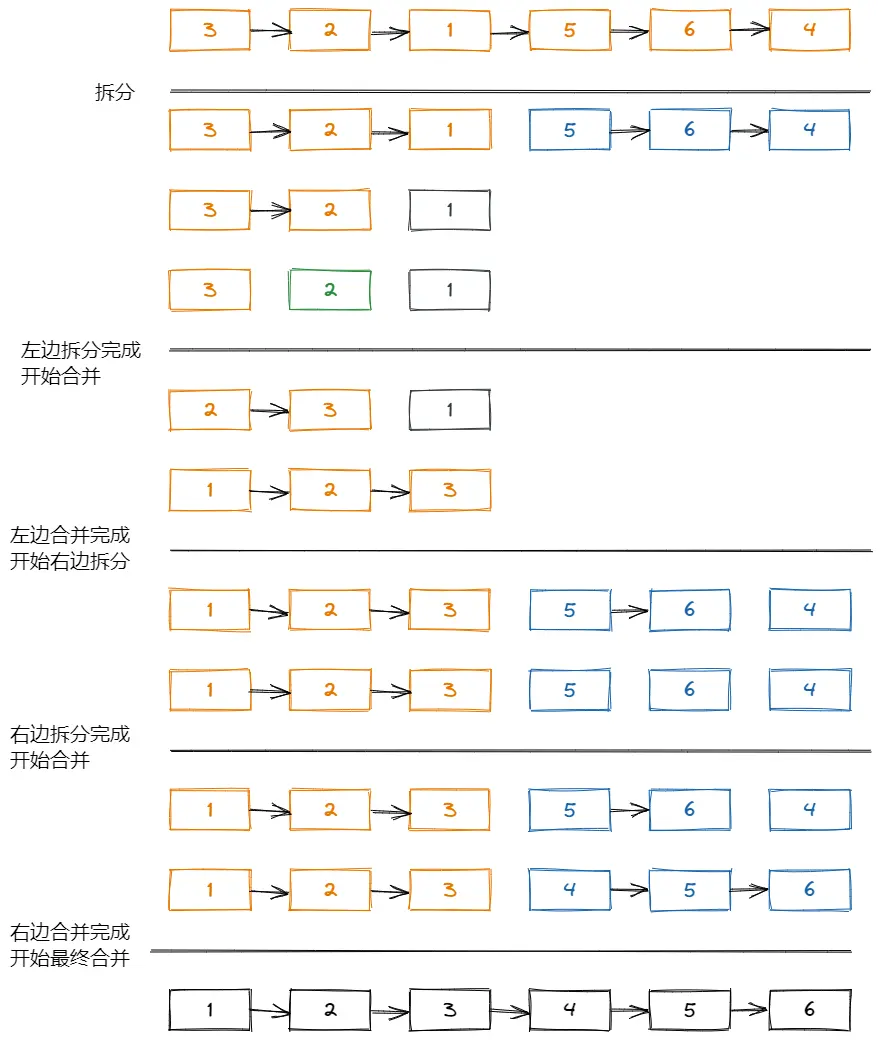
简单的把排序过程花了出来。
整个归并排序,不好理解的地方就是递归拆分的过程,其实也不难理解,就是能拆的情况下就一直拆,直到不能拆了为止。
1 fast := list.Next
2 slow := list
3 for fast != nil && fast.Next != nil {
4 fast = fast.Next.Next
5 slow = slow.Next
6 }
当一次拆分完成时,slow 指针指向的就是链表的中间位置,所以 slow 的 next 就是链表的后半部分了,list 指针就是链表的前半部分。
拆分的过程中有个地方需要注意,就是断链,slow.Next = nil 因为在用快慢指针找到链表的中间位置时,并没有把链表切分开,需要手动把链表断开,要不然从头开始遍历,还是能遍历整个链表的。
总结
链表的问题其实没有没有特别难的算法,基本都是一些基础的操作。链表难的地方是因为内存地址不连续,不像数组那样可以随机访问,只能通过指针操作,理解起来没有那么直观所以会觉难。遇到链表问题就画图,基本上图画出来了,问题也基本能解决了。